To Leverage Data, IT Must First Understand Its Purpose
Consider the bladesmith: He will use several grades of sharpening stones to put a sharp edge on a knife, starting with a coarse-grained stone, moving to a medium-grained stone, and finishing with a fine grain. Information technology can be compared to these sharpening stones. But, instead of sharpening the blade of a knife, it sharpens the competitive edge of the business in the marketplace.
The “coarse stone” of hardware was the focus of the 1990s. Companies went from having no PCs to everyone owning a PC in the blink of an eye. Businesses had to obtain computers in order to compete in the marketplace. Many businesses would no longer be able to operate without the ever-increasing computing power that is often taken for granted.
To continue sharpening the competitive edge into the early 2000s, information technology moved to the “medium stone” of software. Innovative programs were developed by businesses and third parties to streamline processes leveraging the hardware gains to conduct business more efficiently. Those companies that were able to obtain the software to support their customers left those that couldn’t behind.
Hardware and software continue to be pillars of modern day business. Without them there would be no way to handle the millions of transactions that occur within a business day. There would also be no way to collect, manage, and utilize the millions of pieces of data that are used to conduct business. Over the last several years, we now find information technology needs the “fine stone” of data to gain the competitive edge in the marketplace. Those companies that understand and manage their data better are the companies that will compete and thrive in the world market.
[Big Data: Quality Over Quantity]
There are several architectural principles that can be used to conceptualize, design, and implement solutions revolving around a company’s data that are worthwhile to examine. This is the first in a series of four articles that will explore some of the principles that allow a business to leverage its data. The focus of this first article is understanding the purpose of the data. The example that will be used in this article and the rest of the series is the indexing information about document images for an insurance company.
This company saves an image, or an archive, of every insurance document it produces or receives. There is metadata about each of these documents maintained within the imaging system. This metadata provides the information needed to locate and access the millions of insurance document images maintained to support the business. Originally, the archived images were accessed by one application that managed both policies and claims for the insurance business. Over time, the business grew, as did the need for more sophisticated applications. The claims system was segregated away from the policy system into its own application. A portal application was created to provide information exchange with external users. A bulk printing application was designed to print the documents associated with a claim or policy, and a document delivery system was created to produce DVDs containing claim and policy document images. Since all these systems needed to produce or access archived images, they were all connected to the imaging system (IS). See the figure below:
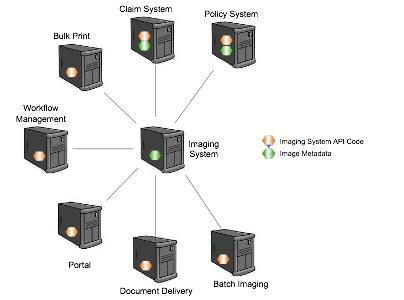
These connections occurred over a period of more than 10 years, and in each case the focus was on implementing a particular component and connecting it to the imaging system. In some cases, the indexing metadata for the documents was stored by the application; in others the metadata was stored in the IS. In this particular example, the IS provided a Java and Windows API interface using what we’ll refer to as IS.jar and IS.dll files to expose the methods needed to interact with the archived images.
Let’s pay particular attention to the index metadata. With very well intentioned customer service in mind, these interface files were individually adjusted over time to provide customized behavior between the IS and the specific business applications. These interfaces and the metadata stored about the images began to diverge, and the system became brittle. It reached a point where there was significant pushback by developers to make any changes to one application interface for fear of the effect the change might have on the IS’s interfaces with the other applications. Additionally, the licensing costs were much greater than they needed to be as each integration was licensed independently.
When the focus is on application development, the time and resources applied seldom have the opportunity to look at the big picture of what is happening in the enterprise. Each specific change is made with good intention, yet incrementally over time the enterprise loses its flexibility to respond to changes, and the infrastructure becomes harder to maintain and less able to adapt to the changing needs of the business.
This raises the question: How do we maintain or even improve the nimbleness and flexibility of the business? As a business we need to respond to customer needs, expanding technology, and changes in the marketplace. It is vital that information technology enable the business to leverage these opportunities as they arise
It may seem odd to call out that IT should understand the data. After all, isn’t this one of its basic duties? Well, those working in IT need to understand data elements and how they are queried, transformed, and presented. However, there are other perspectives that are often overlooked. Is IT taking the time to evaluate the data through the eyes of the business? Are we asking questions like: “How is the business using the data?” “What business value does it provide?” “Who should be able to see this data?” “How will data need to be used?” “Are there other ways this data can be leveraged?”
Back to our example, as the business grew, it became apparent the number of documents generated in support of the claim and policy work had reached a point that the business needed an enterprise solution to build, maintain, and generate claim and policy documents. It is the role of the architecture team to align technology with business needs. In preparation for implementing this document generation component, the team stepped back to look at the big picture and leverage the data. It became clear that there were multiple pain points with the existing solution. After much analysis, the architecture team concluded the metadata used to index the document images needed to be defined for the business as a whole and not based on the specific application.
[Putting customers at the core of modernization efforts]
The team made it its objective to understand what document metadata was important to the business and why. It did not restrict its view to the current application need, and instead sought to understand all the ways in which the metadata was being used by the business and ways it could potentially be used in the future for research, investigations, and business decisions. One takeaway from this exercise was the realization that associating this metadata to document images was an artificial constraint. The essential use of this metadata was to index items, in this case the items were document images. This metadata was named "indexing data" and viewed as the data structure needed to organize any list of items for the enterprise. By focusing on the data needed to index, not only documents, but any set of items, an enterprise index data structure was established. This structure contained information on where the document originated, who the originator was, when it was indexed, and more. A set of index types was created, and each type could be associated with a dynamic set of attributes needed to describe that type. The structure could remain the same, and the data within the structure could uniquely index any group of items.
Taking the time to understand all the use cases that the indexing data must satisfy and developing a structure to do this is part of the framework for a solution that will satisfy the business for the long term. There are other architectural principles to help us leverage enterprise data to keep the business competitive in the marketplace, and these will be the topic of the next three articles in this series.
Andy Metroka is the Director of IT Architecture responsible for systems, application, and database architecture at Montana State Fund, which provides workers compensation insurance for Montana businesses. Prior to that Andy was a software consultant where he designed and ... View Full Bio